Before diving into hands-on coding and practical implementations, it is essential to build a robust mental model of how generative AI systems are constructed, why they succeed, why they fail, and where the technology is heading. Generative AI is not magic. It is a sophisticated, multi-stage engineering pipeline that transforms raw internet data into highly capable reasoning agents. This opening chapter surveys the full landscape — from the atomic units of AI perception to the frontier of agentic systems — so that every concept in the chapters that follow sits on a solid foundation.
The Lifecycle of Intelligence¶
Creating a powerful AI assistant is not a single monolithic task. It is a progressively refined process that begins with absorbing vast quantities of internet text and gradually shapes that raw data into a model that is helpful, aligned with human values, and capable of complex reasoning. The lifecycle unfolds across three distinct stages.
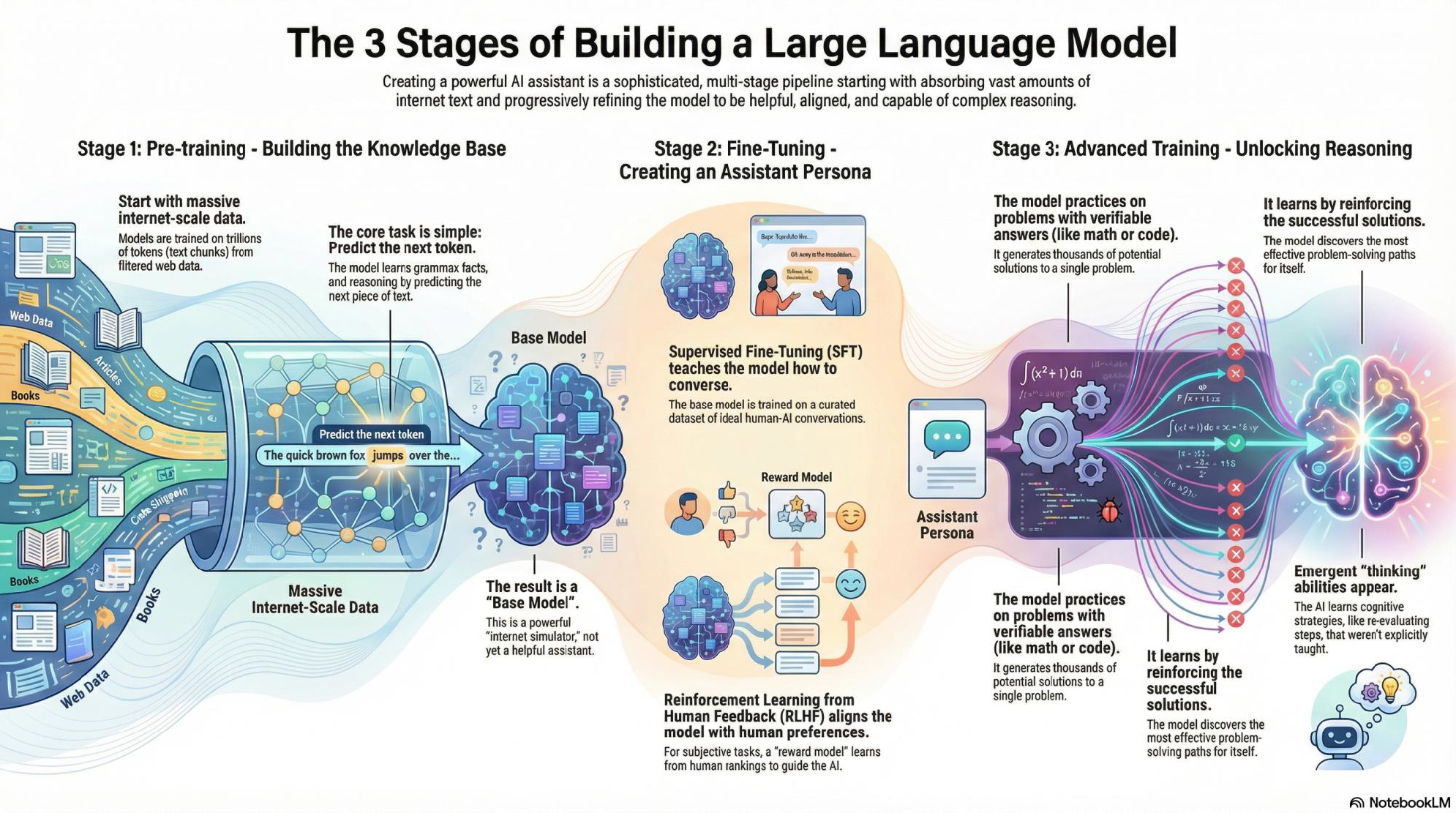
Figure 1:The three stages of building a large language model. Pre-training compresses the internet into a base model; fine-tuning with human feedback turns that base model into a helpful assistant; advanced training on verifiable problems rewards the model for reaching correct answers, from which deliberate reasoning strategies emerge.
Stage 1 — Pre-training builds the foundational knowledge base. Engineers take massive datasets extracted from sources like Common Crawl, representing a snapshot of the public internet — approximately fifteen trillion tokens of text. The core task given to the neural network during this phase is remarkably simple: predict the next token. Through trillions of repetitions the model learns grammar, facts, and rudimentary reasoning purely by predicting the next piece of text. The output of this enormous computational effort is, in essence, a lossy compressed representation of the internet — a web of statistical correlations that captures the patterns of human language.
Stage 2 — Supervised Fine-Tuning (SFT) and Reinforcement Learning transforms the base model from an internet document simulator into a conversational assistant. During SFT, engineers curate a dataset of ideal human-AI conversations and the model learns the format of instruction following. This is what transitions a base model like GPT-3 into InstructGPT, or a raw Llama checkpoint into a chat-ready assistant. The training targets three alignment goals known as the “Three H’s”: the model should be Helpful (actively solve the user’s task), Honest (provide accurate information and admit ignorance), and Harmless (refuse unsafe or illegal requests). After SFT, Reinforcement Learning from Human Feedback (RLHF) further refines the model: human evaluators rank multiple model outputs, a reward model learns from those rankings, and the main model is optimized to maximize its reward score. Through this reinforcement loop the model discovers the most effective ways to interact, aligning closely with human preferences.
Stage 3 — Advanced Training unlocks higher-order reasoning. Standard SFT models have limited working memory and must output a token immediately; they cannot pause to deliberate. Recent advances address this constraint by giving models “tokens to think” — internal reasoning chains that are generated before the final answer. This is the distinction between System 1 thinking (fast, intuitive, pattern-matching) and System 2 thinking (slow, deliberate, logical). Crucially, strategies like backtracking and self-correction are not explicitly programmed. They emerge organically during reinforcement learning when the model is rewarded only for correct final answers. This represents a fundamental shift from imitation to genuine discovery.
Tokenization: How Models See Text¶
Before any of this training can happen, text must be converted into a format the neural network can process. This is where tokenization enters the picture. A tokenizer breaks input text into discrete units called tokens — which may be whole words, subwords, or even individual characters — and maps each to a unique integer from the model’s vocabulary. GPT-4, for example, uses exactly 100,277 unique tokens.
Tokenization has practical consequences that business users encounter regularly. The now-famous “strawberry problem” illustrates this well: when asked how many r’s appear in the word “strawberry,” many models answer incorrectly because the tokenizer encodes the word as something like “Straw” and “berry.” The individual letters are essentially invisible to the model, so it fails at basic character-counting tasks. Understanding tokenization helps explain why LLMs struggle with spelling, letter counting, and certain text manipulations — even when they excel at higher-level language understanding. This is not a failure of reasoning but a direct consequence of how the model perceives text at the token level.
Hallucinations and the Swiss-Cheese Capability¶
Despite rigorous training, generative AI models are not omnipotent. Their intelligence is uneven, leading to what can be called a “Swiss cheese” capability profile. Models can be extraordinarily proficient at translation, coding, and creative writing, yet fail spectacularly at fact-checking, simple arithmetic comparisons, or counting letters.
This statistical nature also leads to hallucinations. Consider the “biography trap”: given the prompt “Who is Orson Kovats?” — a completely fictional name — the model will often confidently generate a detailed biography. It does this because it has read millions of biographies during pre-training and understands the statistical shape of biographical text. When forced to respond, it fills in the blanks of this recognizable pattern, prioritizing statistical fluency over factual accuracy. Understanding this failure mode is critical for business professionals, because it means that LLM outputs must always be verified against authoritative sources. The techniques covered in this book — retrieval-augmented generation, tool use, and grounded agents — are all designed to mitigate this fundamental limitation.
Multimodality: Beyond Text¶
The landscape of generative AI is no longer limited to text. We have entered the era of multimodality, where models can process images, audio, and video alongside language. Under the hood, it is all vectors: models process image pixels and sound waves using the same statistical prediction engines they use for text. Whether the input is a text string, an image, or an audio clip, the data is converted by a unified tokenizer into a sequence of tokens — text tokens, image “patch” tokens, or audio “spectrogram” tokens — and fed into the same transformer architecture as a mixed stream.
This architectural insight explains why the same retrieval-augmented generation pattern that works for text documents (covered in Chapters 8–10) also works for images (Chapter 11) and video (Chapter 11). The retrieval mechanism changes — CLIP embeddings replace text embeddings — but the retrieve-augment-generate pipeline is the same. Understanding multimodality as “the same architecture, different input modalities” demystifies what might otherwise seem like entirely separate technologies.
The Divided Ecosystem¶
Today the AI ecosystem is broadly divided into two camps. Proprietary models from companies like OpenAI (GPT-4, o1), Google (Gemini), and Anthropic (Claude) offer state-of-the-art performance but require API access and come with usage costs. Open-weight models from Meta (Llama), Mistral, Qwen, and others can be downloaded, inspected, and run locally — offering privacy, customization, and freedom from rate limits at the cost of requiring your own compute infrastructure.
For business practitioners, this divide creates a practical decision: use proprietary APIs for maximum capability and minimum operational overhead, or invest in open models for data privacy and cost control at scale. The llm_cascade package used throughout this book bridges this divide by supporting both camps — eight providers spanning proprietary and open-weight models, with automatic fallback when any single provider is unavailable. Chapter 5 covers this in detail.
From Chatbots to Agents¶
The progression of AI capabilities can be viewed across five distinct levels. Level 1 is conversational chatbots. Level 2 is reasoners capable of human-level problem solving. Level 3 is agents that can take autonomous actions. Level 4 is innovators that aid in invention. Level 5 is systems complex enough to do the work of entire organizations.
We are currently sitting between Level 2 and Level 3 — moving beyond models that merely talk to us and stepping into the era of agentic AI, where systems can think, plan, and act. Chapters 16 through 18 of this book trace this progression: from agentic systems that pair single-agent and multi-agent designs, to fully autonomous agents that plan their own research, and finally to tool-using agents connected to real-world services via the Model Context Protocol.
The Path Ahead¶
As you proceed through the hands-on exercises in the following chapters, keep this fundamental advice in mind: treat LLMs as tools, not oracles. You must always own and verify the output. Match the tool to the task — use advanced reasoning models when you need complex logic, and use standard models when you need conversational speed. By understanding the deeply statistical nature of tokenization, the journey from pre-training to reinforcement learning, and the boundaries of current capabilities, you are prepared to harness the true power of generative AI.
The chapters that follow put these concepts into practice. You will build RAG pipelines that ground model answers in retrieved evidence, fine-tune models with QLoRA to bake in new knowledge, construct agent systems that call real tools, and deploy these capabilities to production via MCP servers and no-code platforms. Every notebook is designed to be run on Google Colab — preferably with a T4 GPU, though CPU mode also works — so you can learn by doing, not just by reading.
For a related approach, see LLM Foundations.
Key Takeaways¶
Exercises¶
Easy: Explain in your own words why an LLM trained via next-token prediction can write coherent paragraphs but cannot reliably count the letters in a word. Relate your answer to tokenization.
Easy: Compare proprietary and open-weight models along three dimensions: cost, privacy, and capability. For each dimension, identify which camp has the advantage and why.
Medium: Given the “biography trap” example (the model inventing a biography for a fictional person), design a three-step verification protocol a business analyst should follow before trusting an LLM-generated factual claim.
Challenge: A healthcare startup wants to deploy an LLM for summarizing patient intake forms. Using the five-level AI capability framework from this chapter, identify which level this application requires, what risks exist at that level, and what guardrails (from the techniques previewed in this chapter) you would recommend.
References¶
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35.
Karpathy, A. (2024). Intro to Large Language Models [Video lecture]. YouTube.
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training. OpenAI Technical Report.
Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y. T., Li, Y., Lundberg, S., et al. (2023). Sparks of artificial general intelligence: Early experiments with GPT-4. arXiv preprint arXiv:2303.12712.